TL;DR
En este proyecto me propuse construir una plataforma antifraude event-driven que no solo funcione, sino que también sea operable cuando las cosas se complican.
El pipeline usa persistencia intermedia por etapa: Outbox en transaction-service, Inbox + Outbox en fraud-detection-service e Inbox + deduplicación en alert-service. Con ese diseño, cada salto crítico (persistencia, evaluación, publicación y alerta) mantiene estado recuperable sin bloquear el request path.
El runtime local mantiene defaults de x6 réplicas por microservicio detrás de gateways NGINX, Kafka opera como clúster de 3 brokers y el starter scripts/start-autoscale.sh calcula particiones, concurrencia de listeners y pools de conexión para escalar de forma coherente.
No es solo una demo funcional: es un caso de estudio con resiliencia explícita, trazabilidad end-to-end y validación reproducible (unit + integration + e2e + carga con k6).
Contexto y motivación
Cuando fraude y escritura transaccional viven en el mismo flujo síncrono, compiten por latencia y disponibilidad.
El objetivo práctico fue desacoplar el análisis antifraude sin perder control operacional, con piezas concretas para operar mejor bajo fallos reales:
- consistencia entre DB y publicación de eventos (Outbox),
- desacople consumo/procesamiento con Inbox para absorber picos,
- semántica
at-least-oncecon consumidores idempotentes, - DLQ como mecanismo operativo (no solo “parking lot”),
- observabilidad orientada a negocio y no solo a infraestructura.
Objetivo técnico
El foco técnico es que el pipeline funcione bajo presión sin perder control:
- Mantener alta velocidad de escritura de transacciones.
- Cerrar la brecha de consistencia DB/Kafka en
transaction-serviceyfraud-detection-service. - Escalar procesamiento con particionado real, réplicas e Inbox workers.
- Mejorar triage con trazas, logs estructurados y métricas por etapa.
- Validar comportamiento de forma reproducible con carga mixta y escenarios de error.
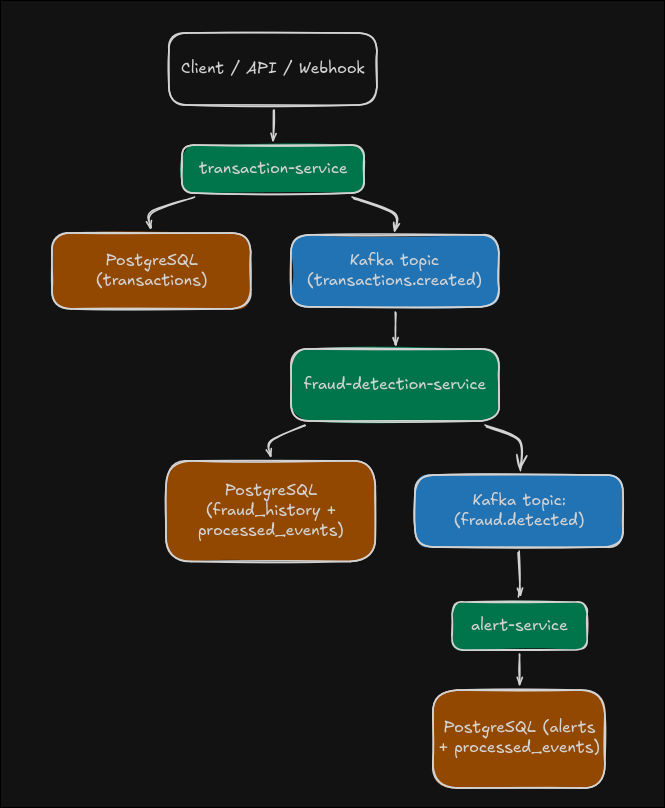
Arquitectura implementada
La arquitectura se organiza en tres dominios funcionales con capa de entrada balanceada y persistencia operativa por etapa:
transaction-gateway(NGINX :8080) ->transaction-service(defaultx6).fraud-gateway(NGINX :8081) ->fraud-detection-service(defaultx6).alert-gateway(NGINX :8082) ->alert-service(defaultx6).
Servicios por responsabilidad:
-
transaction-service- expone API REST + webhook,
- persiste transacción,
- encola
TransactionCreatedEvententransaction_outboxdentro de la misma transacción de BD, - un relay asíncrono publica a Kafka y marca publicados/fallidos.
-
fraud-detection-service- consume
transactions.created, - ingesta en
fraud_inboxcon inserción idempotente poreventId, - procesa inbox con workers, evalúa reglas heurísticas y persiste historial,
- encola
FraudDetectedEventenfraud_outboxcuandoriskScoresupera umbral, - publica
fraud.detectedmediante relay asíncrono desde outbox.
- consume
-
alert-service- consume
fraud.detected, - ingesta en
alert_inboxy procesa con workers, - deduplica por
eventId(inbox +processed_events) y persiste alertas, - notifica por canales (log siempre activo + email opcional con MailHog en local),
- expone consultas de alertas para verificación y triage.
- consume
Cada servicio conserva su base PostgreSQL dedicada y tablas operativas específicas (transaction_outbox, fraud_inbox, fraud_outbox, alert_inbox, processed_events) para desacoplar etapas y sostener recuperación.
Topología Kafka y escalabilidad
El stack local levanta un clúster Kafka de 3 brokers (kafka, kafka-2, kafka-3) con configuración orientada a tolerancia de fallo local:
min.insync.replicas=2- replication factor por defecto
3 - particiones por topic configurables (
APP_KAFKA_PARTITIONS, default18)
Topics principales:
transactions.createdfraud.detectedtransactions.created.dlqfraud.detected.dlq
Esta combinación permite probar paralelismo real por partición y observar mejor el comportamiento de lag/backpressure en escenarios de carga sostenida.
Además, el starter scripts/start-autoscale.sh calcula una configuración consistente de escalado:
partitions = max(instancias_fraud * concurrency_fraud, instancias_alert * concurrency_alert),SPRING_KAFKA_LISTENER_CONCURRENCYpor instancia enfraud-detection-serviceyalert-service,- concurrencia efectiva por consumer group con
min(partitions, instancias * concurrency), - budgets/pools de conexión Hikari por servicio,
- archivo
.env.scalingpara levantardocker composesin editar el compose base.
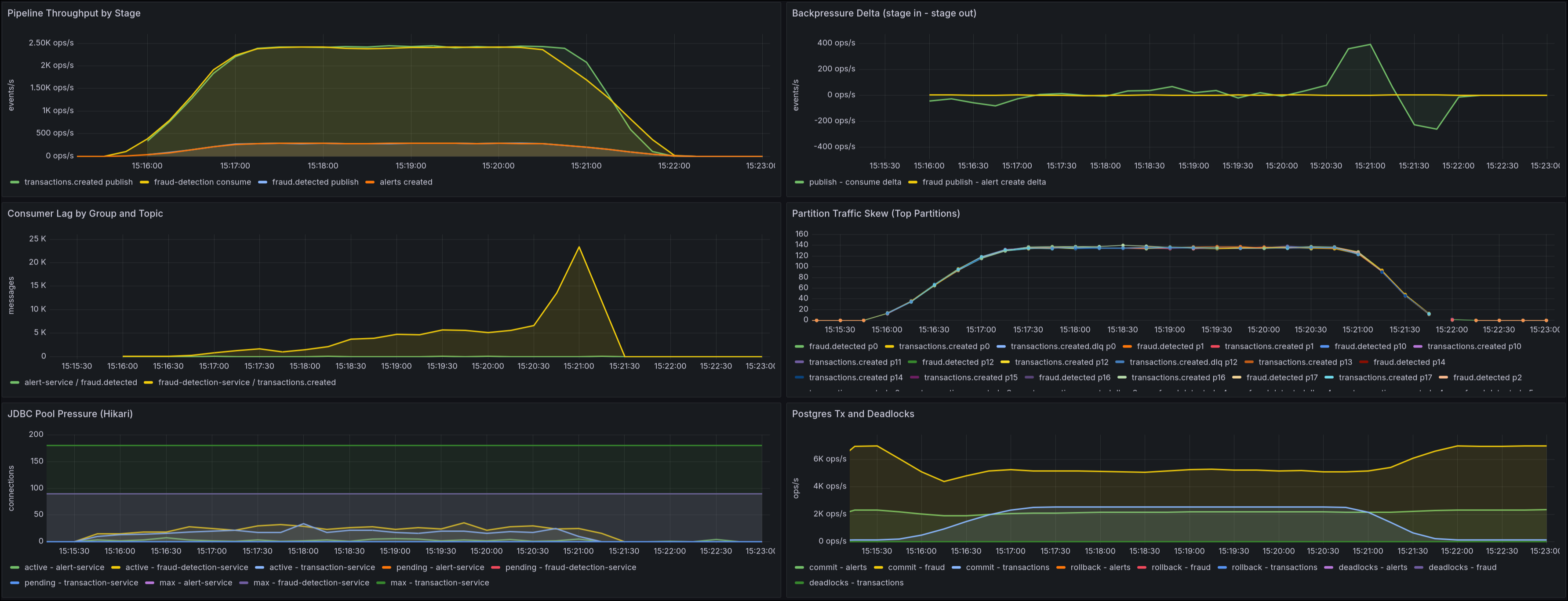
Métricas tras carga sostenida de 2500 RPS con 18 particiones
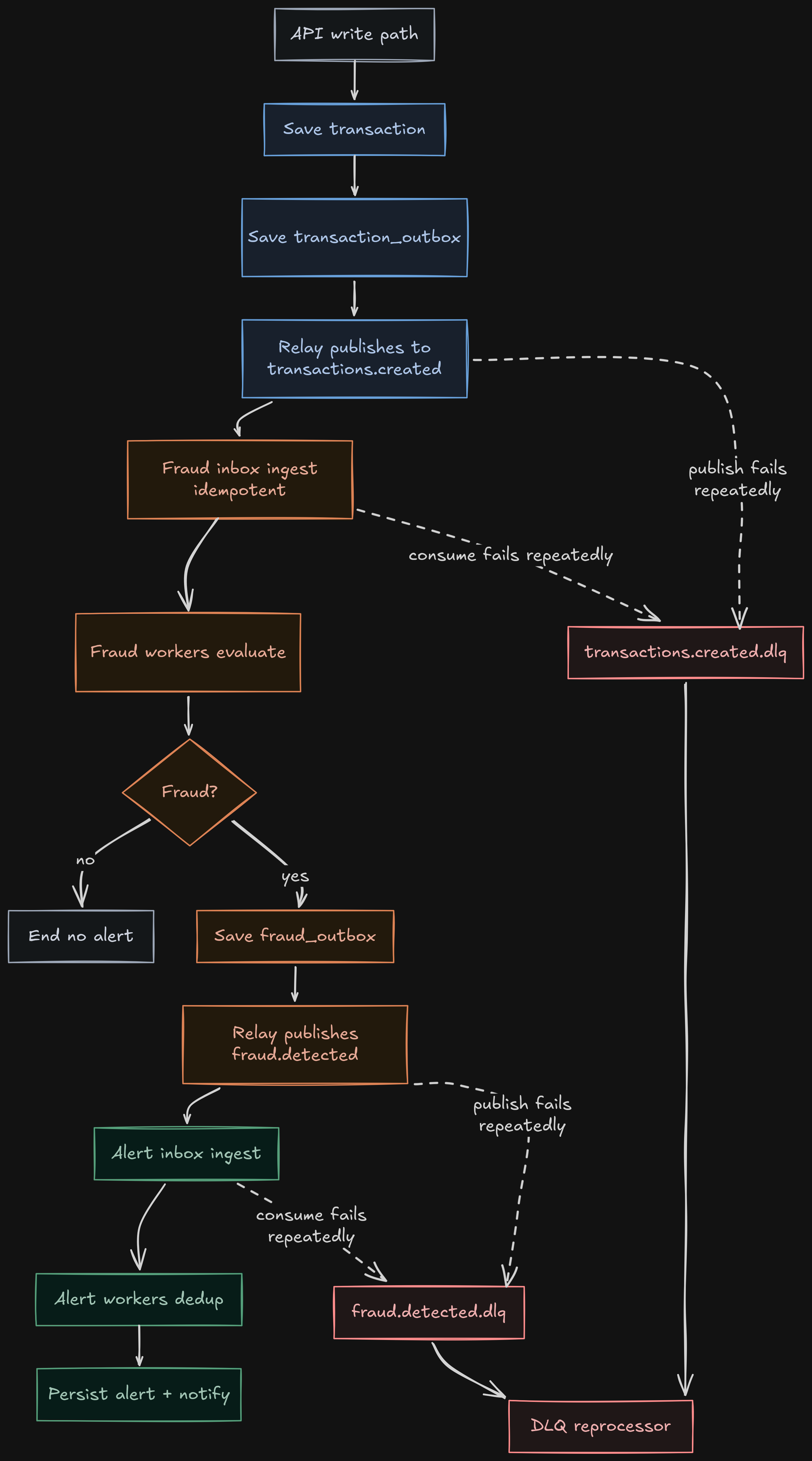
Flujo operativo end-to-end
- Cliente envía transacción por REST o webhook al gateway.
transaction-servicevalida payload, persiste en PostgreSQL y encola evento entransaction_outbox(JSONB).TransactionOutboxRelayServicetoma lote pendiente conFOR UPDATE SKIP LOCKED, publica a Kafka y marca estado (PUBLISHEDo retry connextAttemptAt).fraud-detection-serviceconsumetransactions.createdy encola enfraud_inboxconinsert ... on conflict do nothing.FraudInboxProcessingServicedrena inbox con workers, evalúa reglas y persiste historial de transacciones por usuario.- Si el resultado es
fraud, encolaFraudDetectedEventenfraud_outbox; su relay publica luego enfraud.detected. alert-serviceconsumefraud.detected, encola enalert_inboxy procesa con workers.AlertProcessingServicededuplica (inbox +processed_events), persiste alerta y ejecuta notificaciones por canal.- Si falla consumo, aplica retries con backoff fijo y luego DLQ; consumidores DLQ intentan reproceso y registran métricas de éxito/fallo.
La separación entre escritura síncrona y procesamiento/publicación asíncrona por etapa es clave para mantener latencia estable y consistencia operacional.
Resiliencia y consistencia
Inbox + Outbox por etapa
La plataforma usa persistencia intermedia en cada salto crítico:
transaction-service:transaction_outboxpara desacoplar escritura transaccional y publicación detransactions.created,fraud-detection-service:fraud_inboxpara consumo durable +fraud_outboxpara publicación durable defraud.detected,alert-service:alert_inboxpara desacoplar consumo Kafka y procesamiento de alertas/notificaciones.
Puntos técnicos comunes:
- loteo + lock pesimista no bloqueante (
SKIP LOCKED), - retries con delay configurable,
- cleanup periódico de eventos procesados/publicados,
- propagación de
traceparentybaggagepara conservar continuidad de trazas.
Idempotencia concurrente
La idempotencia se aplica por capa para sostener at-least-once sin efectos duplicados:
fraud-detection-service: deduplicación por clave únicaeventIdenfraud_inbox+ transición explícita de estadoRECEIVED -> PROCESSED,alert-service: deduplicación enalert_inboxy barrera adicional enprocessed_eventscon inserción atómica (saveAndFlush) y manejo deDataIntegrityViolationException.
Retries, DLQ y reproceso operativo
La estrategia de consumo usa backoff fijo (1s, 3 intentos). Si no hay recuperación, el mensaje se deriva a <topic>.dlq.
La DLQ no queda pasiva:
- existen consumidores dedicados por DLQ,
- se registran métricas
received/reprocessed/failed, - hay scripts para forzar y verificar fallo/reproceso (
scripts/test-dlq.sh,scripts/test-dlq-reprocess.sh).
Motor de reglas y contratos de eventos
Reglas de fraude activas
Se mantiene un motor heurístico acumulativo con score cap en 100 y umbral configurable (fraud-score-threshold, default 70).
Reglas activas:
HIGH_AMOUNT(+45)HIGH_VELOCITY(+35)COUNTRY_CHANGE_IN_SHORT_WINDOW(+30)HIGH_RISK_MERCHANT(+25)
El evento FraudDetectedEvent incluye ruleVersion y transactionOccurredAt, lo que facilita trazabilidad de decisiones y medición de latencia end-to-end real del pipeline.
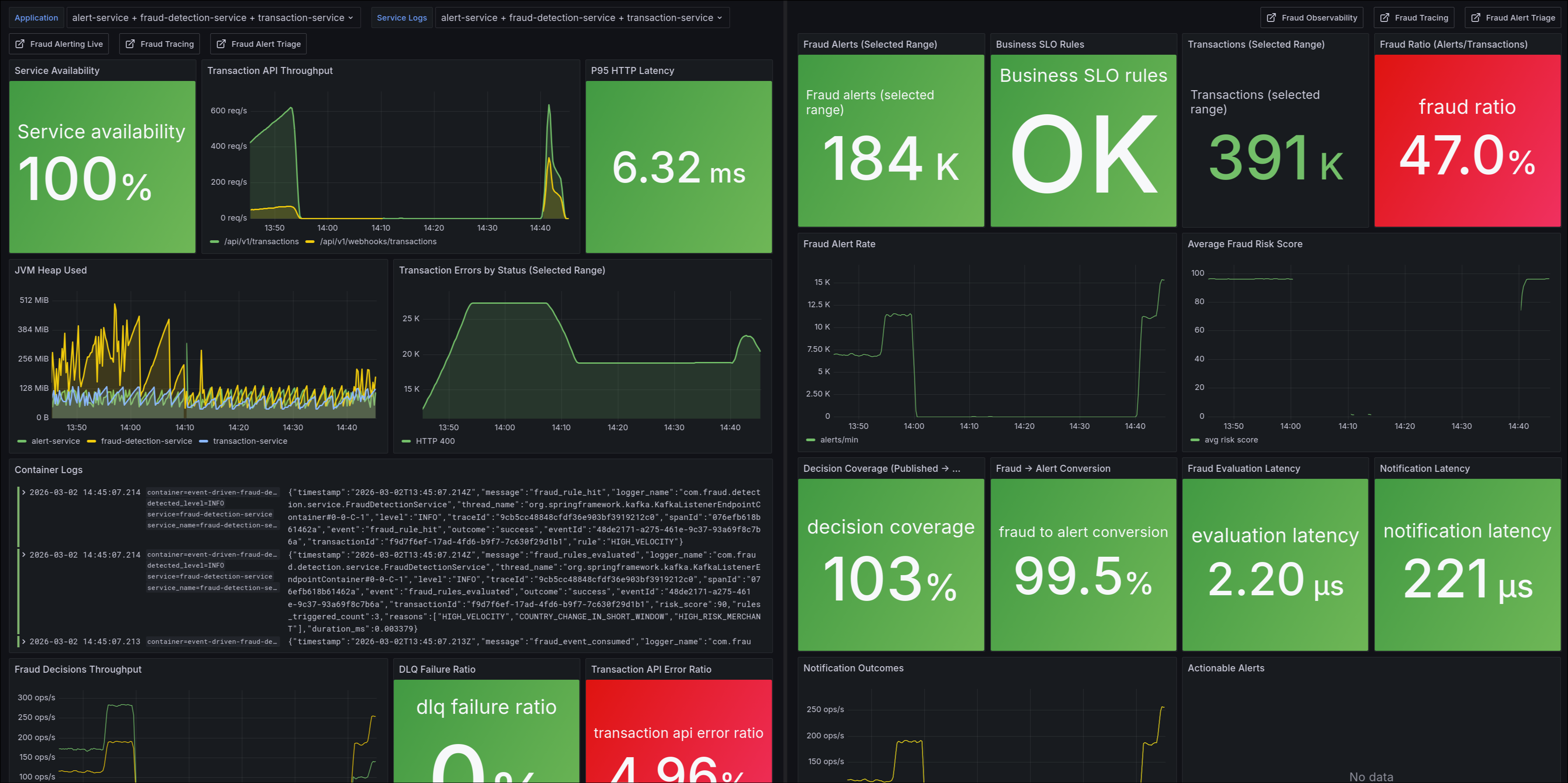
Observabilidad operativa
El stack de observabilidad cubre métricas de aplicación, infraestructura y trazabilidad distribuida:
- Prometheus (servicios + exporters)
- Loki (logs estructurados)
- Alloy (colección de logs Docker + recepción OTLP)
- Tempo (trazas distribuidas)
- Grafana (dashboards y exploración)
- Kafka Exporter + Postgres Exporters + cAdvisor (capacidad e infraestructura)
- contrato operativo de logs JSON (
event+outcome) para filtrar transiciones críticas por servicio.
Dashboards activos:
fraud-observabilityfraud-alerting-livefraud-tracingfraud-alert-triage-dbfraud-kafka-operationsfraud-throughput-livefraud-capacity-backpressure
Métricas que más valor dieron
transaction_events_enqueued_total{outcome}transaction_events_published_total{outcome}fraud_events_consumed_totalfraud_events_published_total{outcome}fraud_decisions_total{decision}fraud_alerts_totalfraud_alert_notifications_total{channel,outcome}fraud_pipeline_e2e_latency_seconds{path}fraud_inbox_backlogalert_inbox_backlogkafka_dlq_events_received_totalkafka_dlq_events_reprocessed_totalkafka_dlq_events_failed_total
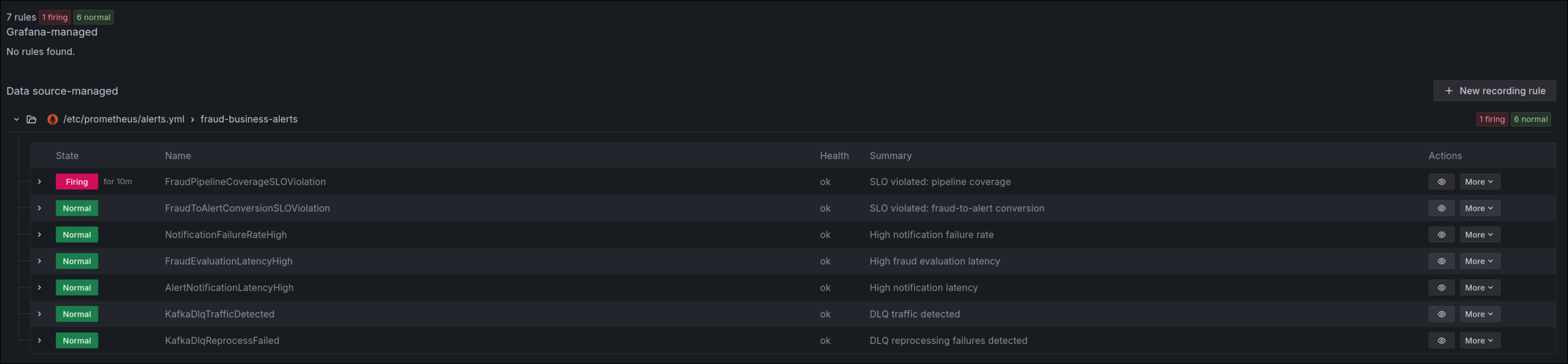
Alertas de negocio y confiabilidad
Se incorporaron reglas de negocio y confiabilidad (incluyendo SLOs de cobertura y conversión):
FraudPipelineCoverageSLOViolationFraudToAlertConversionSLOViolationNotificationFailureRateHighFraudEvaluationLatencyHighAlertNotificationLatencyHighKafkaDlqTrafficDetectedKafkaDlqReprocessFailed
Este conjunto reduce tiempo de detección y evita depender solo de alertas técnicas genéricas.
Validación de comportamiento
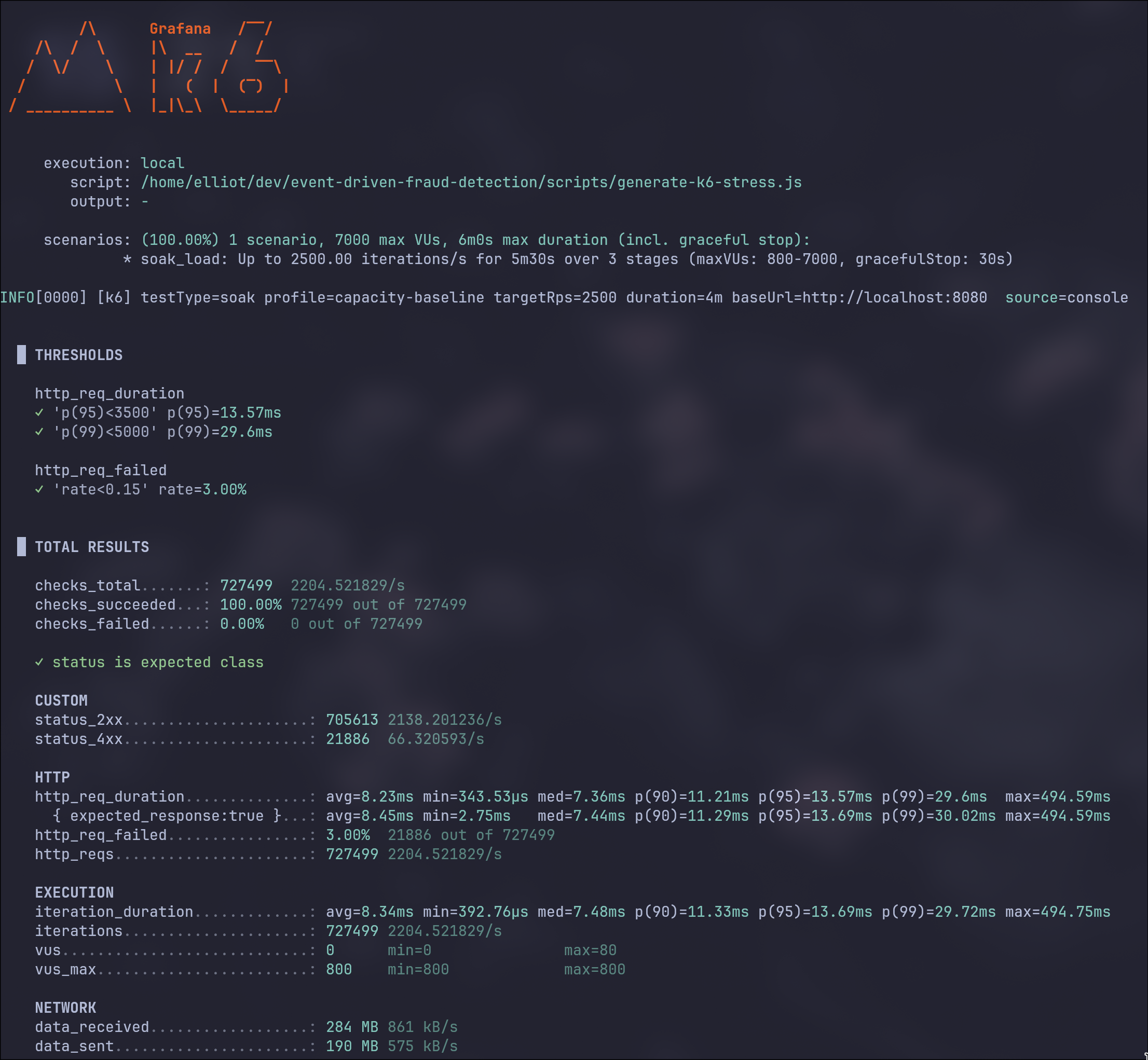
Carga reproducible con k6
El runner de carga está preparado para uso diario y para pruebas comparables:
- modos:
stress,spike,soak,smoke, - perfiles:
capacity-baseline,balanced,mostly-normal,fraud-focus,validation,chaos-5xx,custom, - soporte interactivo y no interactivo,
- validación fuerte de entradas antes de ejecutar,
- fallback con contenedor
grafana/k6cuando no hay binario local.
Esto permite probar no solo throughput, sino también degradación controlada, presión de cola, comportamiento de errores y coherencia de decisiones de fraude.
Pruebas automatizadas
La estrategia combina:
- unit tests,
- integration tests por servicio con Testcontainers (Kafka + PostgreSQL),
- e2e full pipeline con 6 escenarios (incluye carga mixta con asserts de error rate, P95 y materialización de alertas).
También hay workflows CI separados para build/unit, integración y e2e, con retries en e2e y artefactos de diagnóstico en fallo.
Señales de resultado que sí se validan
Más allá de “que compile”, hay condiciones explícitas que el proyecto verifica en automático:
- en
mixedLoad_shouldKeepApiHealthyAndGenerateExpectedAlerts(e2e) se ejecutan 120 requests concurrentes (REST + webhook), - el test exige
errorRate <= 2%yp95 < 2.5sen el path de entrada, - y además confirma que el volumen esperado de fraudes termina materializado como alertas persistidas.
Esto no reemplaza un benchmark productivo, pero sí garantiza una base reproducible para comparar cambios de arquitectura y tuning sin “sensación” subjetiva.
long failedRequests = results.stream().filter(result -> result.statusCode() != 201).count();double errorRate = failedRequests / (double) totalRequests;assertTrue(errorRate <= 0.02, "API error rate should stay below 2% under load");List<Long> latencies = results.stream() .map(LoadResult::latencyMs) .sorted(Comparator.naturalOrder()) .toList();int p95Index = (int) Math.ceil(latencies.size() * 0.95) - 1;long p95LatencyMs = latencies.get(Math.max(0, p95Index));assertTrue(p95LatencyMs < 2500, "P95 latency should stay below 2.5s under load");await() .atMost(Duration.ofSeconds(90)) .pollInterval(Duration.ofSeconds(3)) .untilAsserted(() -> { int currentAlertCount = given() .when() .get(alertServiceUrl + "/api/v1/alerts") .then() .statusCode(200) .extract() .path("size()"); assertTrue(currentAlertCount >= initialAlertCount + fraudulentRequests, "Fraud alerts should be generated for load scenario"); });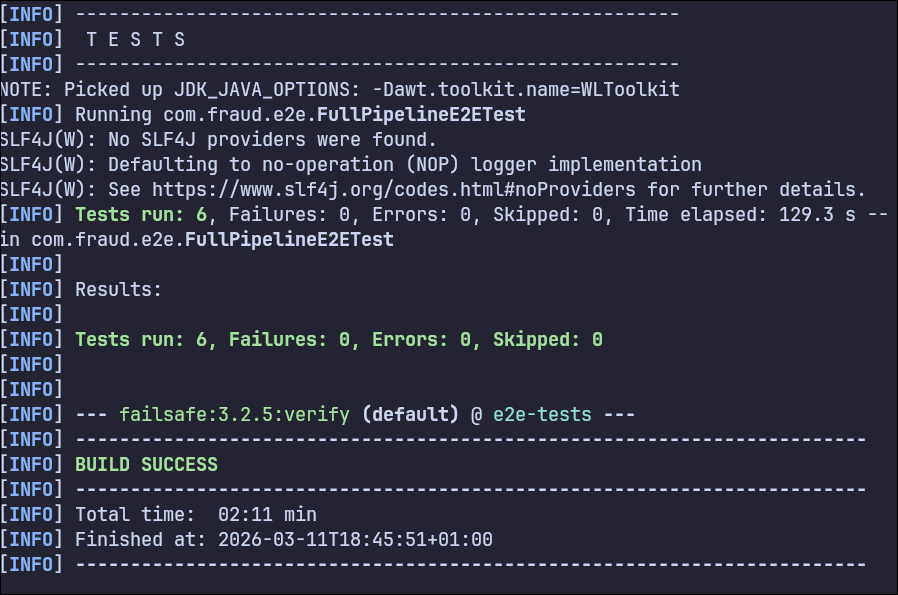
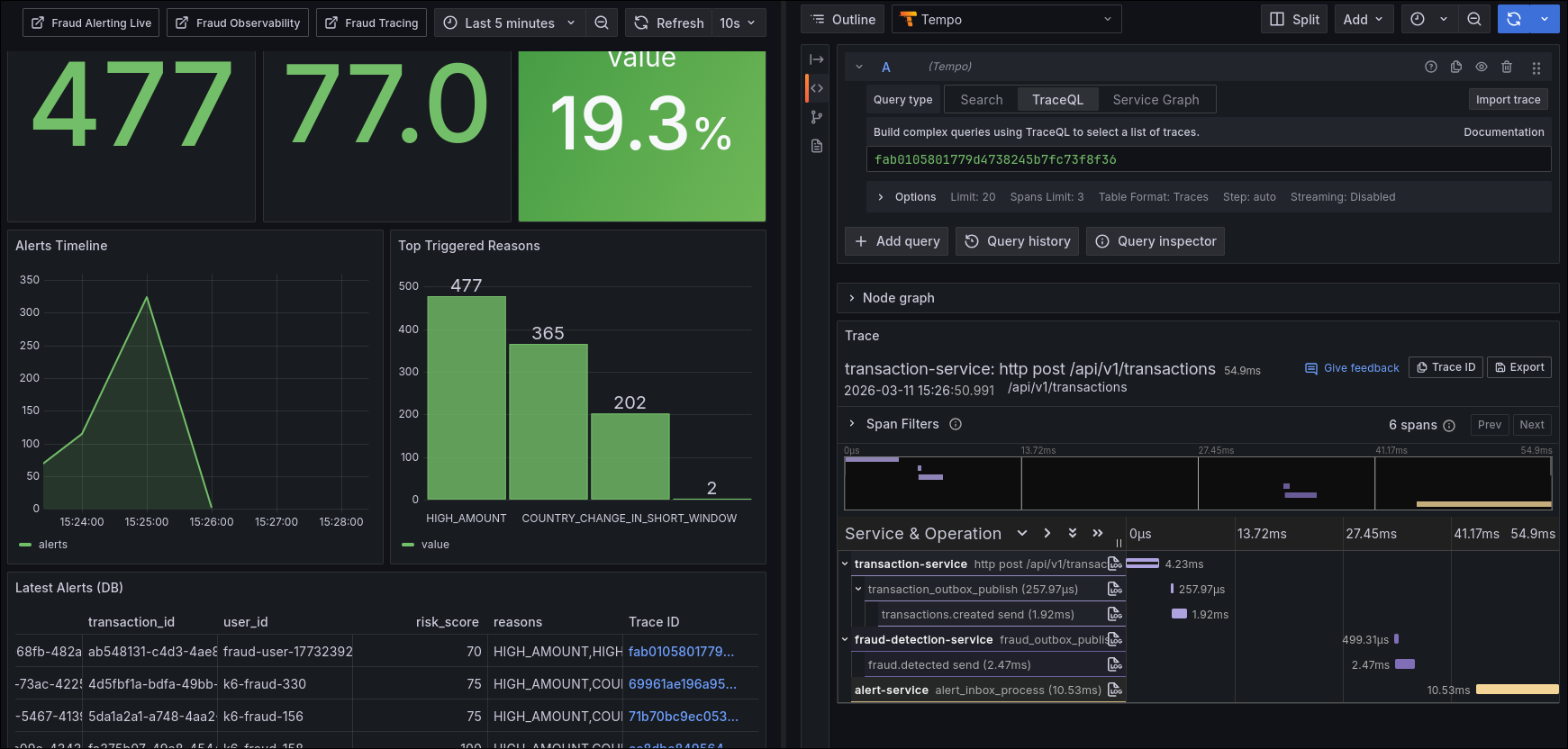
Operación diaria y triage
Flujo operativo recomendado:
- Confirmar salud de pipeline en dashboards de negocio.
- Verificar si el cuello está en backlog de inbox, publish de outbox, evaluación o notificación.
- Correlacionar por
traceIden logs JSON. - Saltar a traza distribuida para secuencia exacta.
Scripts útiles del repositorio:
scripts/start-autoscale.shscripts/single-fraud-scenario.shscripts/run-k6-stress.shscripts/test-dlq.shscripts/test-dlq-reprocess.sh
Garantías implementadas
La plataforma incluye garantías concretas de extremo a extremo:
- menor riesgo de pérdida de eventos en fallos intermedios por persistencia por etapa (inbox/outbox),
- aislamiento entre path síncrono (API) y tramos asíncronos de evaluación/publicación,
- deduplicación explícita para neutralizar reentregas y carreras en consumidores,
- trazabilidad operativa por evento (estado, intentos, errores, latencia y backlog).
Trade-offs asumidos
También hay concesiones deliberadas que forman parte del diseño:
- la consistencia es eventual (no inmediata): la detección/alerta llega milisegundos o segundos después del write inicial,
- aumenta la complejidad operativa (más tablas de estado, workers, políticas de retención y métricas de cola),
- el costo de observabilidad sube, pero se compensa con menor tiempo de diagnóstico cuando hay degradación real.
Deudas técnicas vigentes
| Área | Situación actual | Riesgo | Próximo paso |
|---|---|---|---|
| Contratos de eventos | JSON sin governance formal | Cambios incompatibles silenciosos | Versionado formal + contract tests en CI |
| Esquema de BD | ddl-auto: update aún en uso | Drift entre entornos | Migraciones versionadas (Flyway/Liquibase) |
| Seguridad API | Endpoints sin authN/authZ | Exposición operativa | JWT/OAuth2 + rate limiting |
| Plataforma de despliegue | Foco en Docker Compose local | Brecha frente a producción | Perfil productivo (orquestación + autoscaling) |
También queda por madurar la estandarización fina de nomenclatura de métricas para simplificar mantenimiento de dashboards a largo plazo.
Aprendizajes clave
- Pasar a event-driven sin persistencia intermedia (Inbox/Outbox) deja una brecha de consistencia demasiado costosa en producción.
- La idempotencia en consumidores no es opcional cuando hay
at-least-oncey paralelismo real. - DLQ sin reproceso y métricas dedicadas es deuda operativa disfrazada.
- La observabilidad que realmente acelera triage combina métricas de negocio + logs estructurados + trazas.
- Cargar el sistema con perfiles mixtos (no solo happy path) cambia la calidad de las decisiones de arquitectura.
Cierre personal
Este proyecto me dejó una conclusión práctica: en arquitecturas orientadas a eventos, construir el flujo funcional es solo la mitad del trabajo; la otra mitad es hacerlo observable, recuperable y operable bajo presión.
Eso cambió mi criterio de diseño: ahora priorizo garantías, señales operativas y estrategias de recuperación desde el inicio.