TL;DR
Este proyecto nació como una iniciativa práctica de arquitectura event-driven y se consolidó como una plataforma para aprender de verdad cómo diseñar y operar un pipeline asíncrono que no se rompa en silencio.
La arquitectura se apoyó en tres microservicios transaction-service, fraud-detection-service, alert-service conectados por Kafka, con idempotencia en consumidores, manejo explícito de DLQ y validación bajo carga con k6.
El resultado no fue una promesa abstracta de microservicios, sino un sistema con trade-offs claros, límites conocidos y un camino técnico concreto para evolucionar.
Contexto y motivación
Mi punto de partida fue una inquietud operativa: en un flujo síncrono clásico, la validación antifraude termina compitiendo por tiempo de respuesta con la creación de la transacción.
Eso funciona mientras el volumen es bajo y las reglas son simples. En cuanto aumenta la carga, aparecen reintentos, integraciones, errores parciales y más presión sobre latencia.
La decisión fue separar la persistencia del acto transaccional del análisis antifraude, sin perder trazabilidad del proceso completo.
Objetivo técnico
Definí este objetivo como guía de diseño:
- Registrar transacciones rápido y de forma consistente.
- Evaluar fraude de manera asíncrona con reglas explícitas.
- Generar alertas auditables cuando hay riesgo real.
- Poder detectar degradación antes de que se convierta en incidente.
Ese foco evitó que el proyecto se dispersara en funcionalidades accesorias.
También me dejó una definición útil de éxito técnico para esta etapa: no buscaba complejidad por sí misma, buscaba un flujo antifraude que soportara errores reales sin perder control operativo.
Arquitectura implementada
La arquitectura quedó dividida por contexto de dominio:
transaction-service: recibe REST/webhook, persiste transacción y publicaTransactionCreatedEvent.fraud-detection-service: consume eventos de transacción, evalúa reglas de riesgo y publicaFraudDetectedEventsi aplica.alert-service: consume fraude detectado, persiste alertas y dispara notificaciones.
Cada servicio tuvo su PostgreSQL para mantener independencia de modelo y evolución.
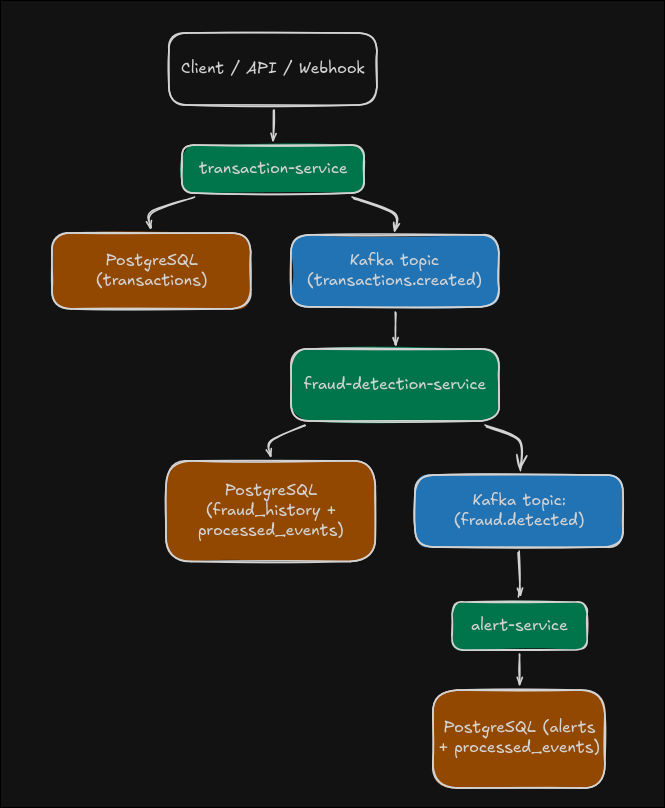
La comunicación se apoyó en Kafka con tópicos principales y sus correspondientes DLQ:
transactions.createdfraud.detectedtransactions.created.dlqfraud.detected.dlq
Decisiones de particionado y escalabilidad
La plataforma se apoyó en tópicos particionados para poder escalar consumidores por grupo y sostener volumen sin convertir cada servicio en un cuello de botella único.
La decisión práctica fue diseñar desde el inicio pensando en procesamiento paralelo, pero manteniendo un modelo de idempotencia que tolerara redelivery y reproceso.
Límite de consistencia asumido
Acepté consistencia eventual entre transacción y alerta. La garantía no fue “todo al mismo tiempo”, sino “todo trazable, recuperable y medible”.
Ese límite fue importante porque evitó falsas promesas y obligó a definir métricas de salud de pipeline, no solo métricas HTTP.
Flujo operativo
- El cliente crea una transacción por REST o webhook.
transaction-servicevalida el payload, persiste y publica evento.fraud-detection-serviceconsume, consulta historial y calculariskScore.- Si el score supera umbral, publica
FraudDetectedEvent. alert-servicepersiste alerta y ejecuta notificación.- Si falla el procesamiento, el evento va a DLQ para análisis y reproceso.
Este flujo separó bien latencia de escritura y latencia de análisis, que era el principal conflicto del enfoque síncrono.
Punto de control por etapa
Para que el flujo no quedara como una caja negra, definí señales claras por etapa:
- Entrada: volumen recibido por canal (REST/webhook) y validaciones fallidas.
- Publicación: éxito/fallo al enviar eventos a Kafka.
- Evaluación: decisiones
clean/fraudy latencia de reglas. - Alertado: alertas creadas y resultado de notificaciones por canal.
- Recuperación: tráfico DLQ, reprocesos exitosos y reprocesos fallidos.
Esa separación hizo mucho más simple localizar degradaciones sin saltar directamente a revisar todo el sistema.
Resiliencia y consistencia
Donde más valor aportó el diseño fue en control de efectos bajo semántica at-least-once.
Idempotencia de consumidores
Implementé idempotencia por eventId en una tabla processed_events con inserción atómica (saveAndFlush) y captura de DataIntegrityViolationException para tratar duplicados bajo concurrencia. Así, un mensaje duplicado no volvió a crear efectos de negocio.
Retries y DLQ
Configuré retries con backoff fijo y desvío a DLQ cuando el evento no pudo procesarse.
Reproceso explícito
No dejé la DLQ como almacén pasivo: la traté como parte del flujo operativo, con métricas y lógica de reproceso.
Qué problema evité con esta estrategia
Sin idempotencia + DLQ operada, un incidente de consumidor podía terminar en dos daños simultáneos: pérdida de visibilidad y duplicación de efectos.
Con la estrategia actual, cuando algo falla:
- El evento no desaparece, queda identificado.
- El fallo se vuelve visible por métricas y alertas.
- Existe una vía explícita de recuperación.
No eliminé los fallos, pero sí reduje su impacto y su tiempo de diagnóstico.
Trade-off que quedó pendiente
El punto más sensible siguió siendo el dual-write DB/Kafka en transaction-service.
Elegí ese camino para avanzar en flujo y observabilidad, sabiendo que el cierre robusto de consistencia debía llegar con Transactional Outbox.
Motor de reglas de fraude
El motor se mantuvo heurístico, con reglas acumulativas de score y umbral configurable.
Ese enfoque me permitió dos ventajas prácticas:
- Explicabilidad inmediata de por qué se disparó una alerta.
- Iteración rápida sobre reglas sin depender de un pipeline de entrenamiento.
Las señales principales que utilicé fueron monto, velocidad transaccional, cambio de país y merchants de riesgo.
Por qué no introduje ML en esta fase
No fue por desinterés técnico. Fue una decisión de secuencia.
Sin una base sólida de contratos, calidad de datos, observabilidad y operación de incidentes, incorporar ML habría aumentado complejidad sin mejorar realmente la confiabilidad del sistema.
Contratos de eventos
El intercambio entre servicios se apoyó en eventos JSON versionables por diseño, aunque todavía sin gobernanza formal de esquema.
El aprendizaje fue claro: en arquitecturas event-driven, cambiar un payload “pequeño” puede romper consumidores aguas abajo de forma silenciosa si no hay disciplina de compatibilidad.
Por eso dejé como siguiente paso formalizar:
- Versionado explícito de eventos.
- Validación de contrato en CI.
- Reglas de backward compatibility para productores y consumidores.
Fragmento de código representativo
Este método resume el orden que seguí para evitar inconsistencias: deduplicar, evaluar, persistir trazabilidad y publicar.
@Transactionalpublic void process(TransactionCreatedEvent event) { fraudDetectionMetrics.recordEventConsumed(); String traceId = resolveTraceId(event.traceId()); long lagMs = event.occurredAt() == null ? 0 : Math.max(0, Instant.now().toEpochMilli() - event.occurredAt().toEpochMilli()); log.info("fraud_event_consumed", kv("event", "fraud_event_consumed"), kv("outcome", "success"), kv("eventId", event.eventId()), kv("transactionId", event.transactionId()), kv("lag_ms", lagMs) );
Instant occurredAt = event.occurredAt() != null ? event.occurredAt() : Instant.now();
if (!tryMarkAsProcessed(event.eventId(), occurredAt)) { log.info("fraud_event_duplicate", kv("event", "fraud_event_duplicate"), kv("outcome", "duplicate"), kv("eventId", event.eventId()), kv("transactionId", event.transactionId()) ); return; }
long recentTransactionsCount = historyRepository.countByUserIdAndOccurredAtAfter( event.userId(), occurredAt.minus(rules.getVelocityWindow()) );
Optional<UserTransactionHistory> lastTransaction = historyRepository.findTopByUserIdOrderByOccurredAtDesc(event.userId());
long evaluationStartNanos = System.nanoTime(); FraudEvaluation evaluation = fraudRulesEngine.evaluate(event, lastTransaction, recentTransactionsCount, occurredAt); long evaluationDurationNanos = System.nanoTime() - evaluationStartNanos; fraudDetectionMetrics.recordEvaluationNanos(evaluationDurationNanos); double evaluationDurationMs = evaluationDurationNanos / 1_000_000.0; log.info("fraud_rules_evaluated", kv("event", "fraud_rules_evaluated"), kv("outcome", "success"), kv("eventId", event.eventId()), kv("transactionId", event.transactionId()), kv("risk_score", evaluation.riskScore()), kv("rules_triggered_count", evaluation.reasons().size()), kv("reasons", evaluation.reasons()), kv("duration_ms", evaluationDurationMs) );
for (String rule : evaluation.reasons()) { fraudDetectionMetrics.recordRuleHit(rule); log.info("fraud_rule_hit", kv("event", "fraud_rule_hit"), kv("outcome", "success"), kv("eventId", event.eventId()), kv("transactionId", event.transactionId()), kv("rule", rule) ); }
historyRepository.save(userTransactionHistoryMapper.toHistory(event, occurredAt));
if (!evaluation.fraudulent()) { fraudDetectionMetrics.recordDecision("clean"); log.info("fraud_decision_made", kv("event", "fraud_decision_made"), kv("outcome", "clean"), kv("eventId", event.eventId()), kv("transactionId", event.transactionId()), kv("decision", "clean"), kv("risk_score", evaluation.riskScore()), kv("rule_version", RULE_VERSION) ); return; }
fraudDetectionMetrics.recordDecision("fraud"); log.warn("fraud_decision_made", kv("event", "fraud_decision_made"), kv("outcome", "fraud"), kv("eventId", event.eventId()), kv("transactionId", event.transactionId()), kv("decision", "fraud"), kv("risk_score", evaluation.riskScore()), kv("reasons", evaluation.reasons()), kv("rule_version", RULE_VERSION) );
FraudDetectedEvent fraudDetectedEvent = fraudDetectedEventMapper.toFraudDetectedEvent( event, evaluation, UUID.randomUUID().toString(), Instant.now(), traceId, RULE_VERSION ); try { fraudEventPublisher.publish(fraudDetectedEvent); fraudDetectionMetrics.recordFraudEventPublished("success"); log.info("fraud_event_published", kv("event", "fraud_event_published"), kv("outcome", "success"), kv("eventId", fraudDetectedEvent.eventId()), kv("transactionId", fraudDetectedEvent.transactionId()), kv("risk_score", fraudDetectedEvent.riskScore()) ); } catch (IllegalStateException ex) { fraudDetectionMetrics.recordFraudEventPublished("failed"); log.error("fraud_event_publish_failed", kv("event", "fraud_event_publish_failed"), kv("outcome", "failed"), kv("eventId", fraudDetectedEvent.eventId()), kv("transactionId", fraudDetectedEvent.transactionId()), kv("error_code", "KAFKA_PUBLISH_FAILED"), kv("error_class", ex.getClass().getSimpleName()), kv("error_message", ex.getMessage()) ); throw ex; }}Ese orden redujo efectos indeseados en escenarios de redelivery y dejó más claro dónde instrumentar cuando aparecieron errores intermitentes.
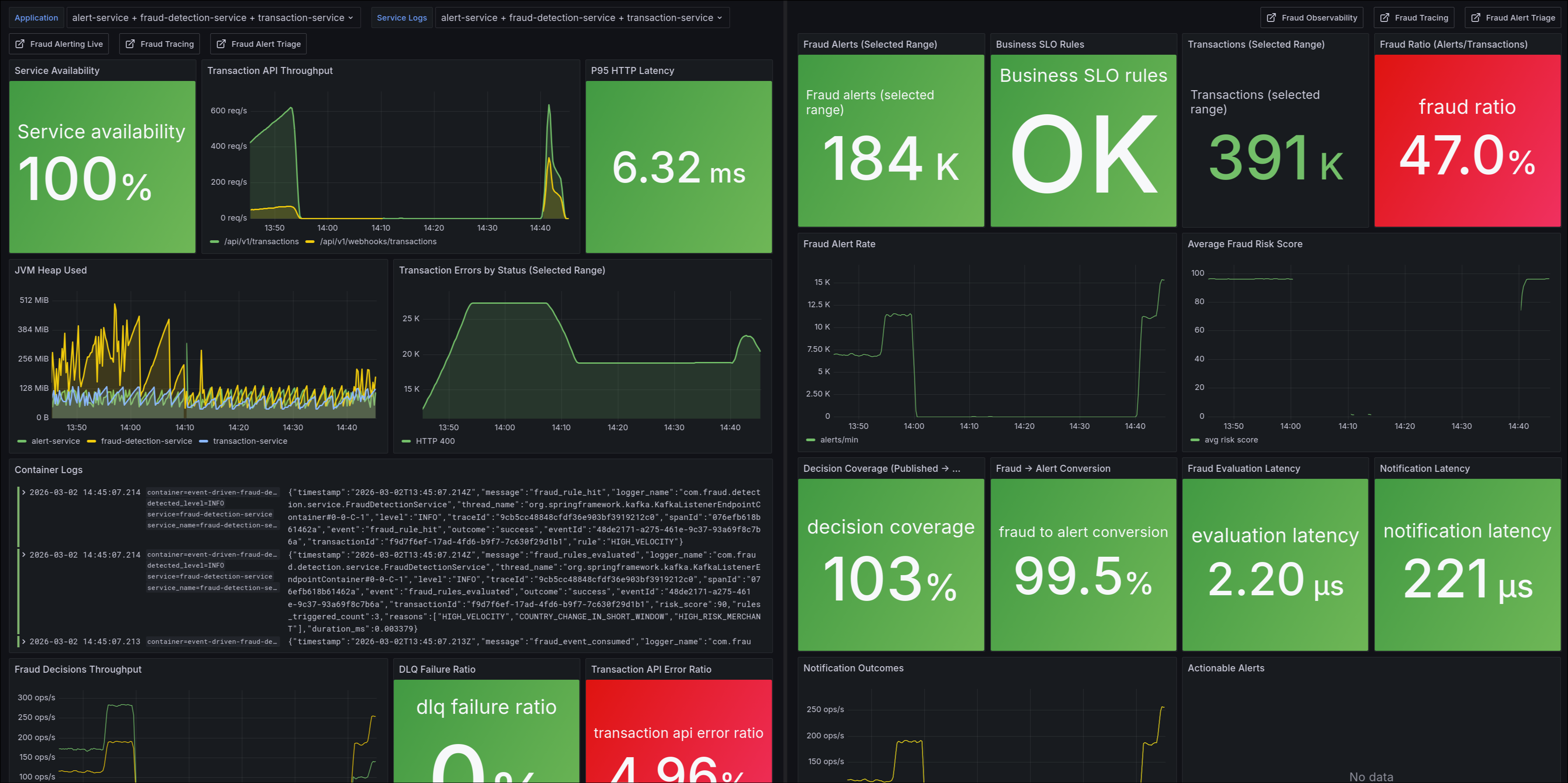
Observabilidad operativa
La observabilidad no entró al final: la traté como requisito estructural.
- Métricas con Prometheus.
- Logs estructurados con Loki.
- Trazas distribuidas con Tempo.
- Dashboards de operación y triage en Grafana.
Dashboards destacados:
fraud-observabilityfraud-alerting-livefraud-tracingfraud-alert-triage-db
También incorporé reglas de alertado con enfoque de negocio (coverage, conversión fraude->alerta, latencias y fallos de notificación).
Métricas que más valor aportaron
Más allá de CPU/memoria, las métricas que marcaron diferencias fueron las de comportamiento del negocio:
transactions_received_totalfraud_decisions_total{decision}fraud_alerts_totalfraud_alert_notifications_total{channel,outcome}kafka_dlq_events_received_totalkafka_dlq_events_reprocessed_total
Con ese conjunto pude responder preguntas concretas durante pruebas e incidentes: cuántas transacciones llegaron, cuántas se evaluaron, cuántas terminaron en alerta y dónde se degradó el flujo.
Logs y trazas con contexto útil
Los logs estructurados con traceId y spanId permitieron pasar de una alerta en panel a una traza específica sin navegación manual excesiva.
Ese puente entre métricas, logs y trazas fue lo que convirtió la observabilidad en herramienta operativa real, no en un tablero “bonito”.
Validación de comportamiento bajo carga
Para validar comportamiento real, pasé de scripts ad-hoc a una estrategia reproducible con k6.
- Modos de prueba:
stress,spike,soak,smoke. - Perfiles de payload:
balanced,mostly-normal,fraud-focus,validation,chaos-5xx. - Ejecución interactiva o no interactiva, local o vía Docker.
Esto permitió observar no solo throughput, sino también degradación de latencia, resiliencia ante errores y estabilidad del pipeline de eventos.
Qué busqué en las pruebas
No busqué únicamente “más RPS”. Busqué validar cuatro preguntas concretas:
- Si aumentaba el tráfico, ¿la API seguía respondiendo dentro de umbrales razonables?
- Si subía el porcentaje de payload inválido, ¿el sistema degradaba de forma controlada?
- Si forzaba escenarios de error, ¿la DLQ absorbía correctamente y quedaba trazabilidad?
- Si el tráfico era mixto, ¿el ratio de decisiones y alertas seguía siendo coherente?
Esa perspectiva hizo que la carga se usara como validación de arquitectura y no solo como benchmark superficial.
Estrategia de pruebas
Combiné tres niveles para cubrir desde lógica hasta flujo completo:
- Unitarias para reglas de fraude y componentes de dominio.
- Integración con Testcontainers (Kafka + PostgreSQL) para validar interacción real entre infraestructura y código.
- E2E para comprobar el recorrido completo desde creación de transacción hasta materialización de alerta.
Esta combinación redujo huecos entre lo que “parecía correcto” en unit tests y lo que realmente ocurría cuando intervenían brokers, commits y reintentos.
Operación diaria y triage
Una parte importante del trabajo estuvo en definir cómo investigar rápido cuando algo salía mal.
Flujo de triage que seguí:
- Verificar señales globales en dashboards de negocio.
- Confirmar si el problema estaba en publicación, consumo o notificación.
- Correlacionar con logs estructurados por
traceId. - Abrir traza distribuida para entender la secuencia exacta.
- Revisar métricas de DLQ para decidir reproceso o intervención.
Este enfoque evitó diagnósticos por intuición y mejoró la velocidad de respuesta ante incidencias.
Lo que quedó fuera (de forma consciente)
Esta versión dejó fuera piezas importantes para no perder foco de arquitectura base:
- Seguridad completa en endpoints (authN/authZ y rate limiting por actor).
- Transactional Outbox para cerrar dual-write DB/Kafka.
- Gobernanza formal de contratos de eventos (versionado y validación de esquema).
- Motor de fraude avanzado (segmentación y estrategias adaptativas).
No fue omisión accidental: fue priorización para estabilizar primero la columna vertebral del sistema.
Esa priorización también ayudó a no mezclar capas: primero robustecí flujo, señales y recuperación; después planifiqué endurecimiento de seguridad, contratos y evolución del motor.
Deudas técnicas principales
| Área | Situación actual | Riesgo | Próximo paso |
|---|---|---|---|
| DB + Kafka | Dual-write en transaction-service | Desalineación en fallos raros | Outbox + relay |
| Esquema de BD | Uso parcial de ddl-auto | Drift de esquema | Migraciones versionadas (Flyway/Liquibase) |
| Contratos de evento | JSON sin governance formal | Breaking changes silenciosos | Versionado + validación de contrato |
| Seguridad | Endpoints abiertos | Exposición operativa | JWT/OAuth2 + rate limiting |
Además, dejé identificado un frente adicional: homogeneizar naming de métricas para evitar paneles ambiguos cuando la plataforma siga creciendo.
Aprendizajes clave
- En distribuido, el reto principal no fue enviar mensajes, sino controlar consecuencias de fallos parciales.
- La idempotencia dejó de ser recomendación y pasó a ser requisito mínimo.
- Una DLQ sin proceso operativo fue deuda escondida.
- La observabilidad temprana acortó muchísimo el tiempo de diagnóstico.
- Definir alcance técnico con honestidad aceleró más que intentar cubrir todo a la vez.
Próximos pasos
- Implementar Transactional Outbox para consistencia fuerte entre DB y publicación de eventos.
- Endurecer seguridad de APIs y notificaciones.
- Formalizar contratos de eventos con compatibilidad hacia atrás.
- Evolucionar reglas antifraude con experimentación controlada por segmentos.
Cierre
Este proyecto me dejó una conclusión práctica: en arquitecturas orientadas a eventos, construir el flujo funcional es solo la mitad del trabajo; la otra mitad es hacerlo observable, recuperable y operable bajo presión.
Eso cambió mi criterio de diseño: ahora priorizo garantías, señales operativas y estrategias de recuperación desde el inicio.